手绘拼豆图纸?我选择Python!
前言 最近我老婆迷上了拼豆。 什么是拼豆? 拼豆就是将各种颜色的小豆子拼在一起,通过熨烫成塑料画,在现实中实现各种像素画。 放一张我老婆给我做的拼豆为例,就很容易理解了: ! (https://api.flowersink.com/uploads/blog/images/compressed 1743401100136
前言
最近我老婆迷上了拼豆。
什么是拼豆?拼豆就是将各种颜色的小豆子拼在一起,通过熨烫成塑料画,在现实中实现各种像素画。
放一张我老婆给我做的拼豆为例,就很容易理解了:

当然,拼豆和编程、技术很难关联在一起,为什么会诞生这篇博客呢,还需要再讲讲拼豆中最重要的东西:图纸
拼豆的图纸
拼豆是像素画,是由一个一个的豆子(像素)拼起来的。
拼豆过程是用镊子将一个个极小的颗粒按像素画的布局进行摆放,所以不可能在拼豆的过程中进行绘制,那就需要提前获取图纸,用来作为拼豆的参考。
而给拼豆的玩家一张像素画,它就可以按照像素画一颗一颗豆的拼出来了吗?并不是的
我们以经典像素画风游戏Minecraft中的胡萝卜为例,它的原画是这样的:

在拼豆中,面对这样的原画/像素画,颜色虽然有上百种,但也是完全提前固定好的颜色,不像现实绘画可以自由调色,并且还存在以下问题:
1.这张画需要什么颜色的豆子?每种颜色需要多少豆子?
2.这张画的尺寸是多大?如果超过50*50那就无法单用一个画板进行绘制了。
3.没有参考线,一旦画错,所付出的成本是很大的。
那么胡萝卜的图纸是怎么样的呢,请看下图:
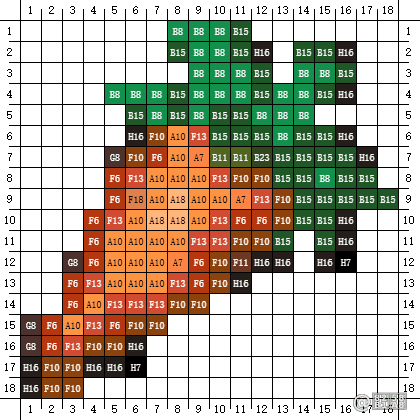
所以,只要有图纸,拼豆玩家就可以通过图纸所需要的豆子颜色、豆子数量、大小进行提前准备(毕竟拼豆全颜色一套下来要接近1000+RMB!)
然而网络上图纸的资源并不多,尤其是我和我老婆很喜欢的Minecraft图纸,几乎没有资源。如何获取图纸成为了最大的难题。
获取图纸
获取图纸的第一步是获取Minecraft中各类物品的原图原画。
如果想要获取MC的物品原图,有一个笨方法就是去游戏里一个一个截,当然如果我采用这种笨方法就不会有这篇博客了……
我在逛Minecraft WIKI的时候,突然想到了爬虫。
编写爬虫
从网络中可以得知,Minecraft的维基百科API为https://minecraft.fandom.com/api.php
于是我们可以很轻易的通过API去抓取我们所需要的所有物品原画,先定义一些基础信息,例如安装库、API地址、保存路径、抓取类别和正则表达式:
import os
import requests
import re
# Minecraft 维基百科 API
WIKI_API_URL = "https://minecraft.fandom.com/api.php"
# 本地保存路径
SAVE_DIR = "minecraft_items"
os.makedirs(SAVE_DIR, exist_ok=True)
# 需要抓取的物品类别
CATEGORIES = [
"Items", "Blocks", "Tools", "Weapons", "Armor", "Food", "Brewing", "Materials"
]
# 过滤非法字符的正则
INVALID_FILENAME_CHARS = r'[<>:"/\\|?*]'
def sanitize_filename(filename):
"""移除 Windows 文件名中的非法字符"""
return re.sub(INVALID_FILENAME_CHARS, "", filename)
先获取所有物品
def get_items_from_category(category):
""" 获取指定类别下的所有物品 """
item_list = []
params = {
"action": "query",
"format": "json",
"list": "categorymembers",
"cmtitle": f"Category:{category}",
"cmlimit": "max"
}
while True:
response = requests.get(WIKI_API_URL, params=params)
data = response.json()
items = data.get("query", {}).get("categorymembers", [])
item_list.extend([item["title"] for item in items])
# 处理分页情况,若 API 返回 "continue",则继续请求下一页数据
if "continue" in data:
params.update(data["continue"])
else:
break
return item_list
获取物品的图片和分类(方便按文件夹文类保存)
def get_item_image_and_category(item_name):
""" 获取物品的图片 URL 和分类 """
params = {
"action": "query",
"format": "json",
"prop": "pageimages|categories",
"titles": item_name,
"piprop": "original"
}
response = requests.get(WIKI_API_URL, params=params)
data = response.json()
pages = data.get("query", {}).get("pages", {})
image_url = None
categories = []
for page in pages.values():
if "original" in page:
image_url = page["original"]["source"] # 提取图片 URL
if "categories" in page:
categories = [cat["title"].replace("Category:", "") for cat in page["categories"]] # 获取物品所属分类
return image_url, categories
编写主函数,将图片下载到本地并分类、在命令行中展示结果
def download_image(url, item_name, category):
""" 下载图片并按类别保存,避免重复下载 """
if not url:
print(f"[跳过] {item_name} 没有找到图片")
return
# 处理非法字符
safe_item_name = sanitize_filename(item_name)
# 确保分类文件夹存在
category_dir = os.path.join(SAVE_DIR, category)
os.makedirs(category_dir, exist_ok=True)
# 目标文件路径
filename = os.path.join(category_dir, f"{safe_item_name}.png")
# **跳过已下载文件**
if os.path.exists(filename):
print(f"[已存在] {safe_item_name} (分类: {category}),跳过下载")
return
# 下载图片
response = requests.get(url, stream=True)
if response.status_code == 200:
with open(filename, "wb") as file:
for chunk in response.iter_content(1024):
file.write(chunk)
print(f"[成功] {safe_item_name} 下载完成 (分类: {category})")
else:
print(f"[失败] 无法下载 {safe_item_name}")
if __name__ == "__main__":
all_items = {}
for category in CATEGORIES:
items = get_items_from_category(category)
print(f"在 {category} 分类下找到 {len(items)} 个物品")
for item in items:
all_items[item] = category # 记录物品所属类别
print(f"总共找到 {len(all_items)} 个物品")
for item, category in all_items.items():
image_url, item_categories = get_item_image_and_category(item)
# 选取最匹配的分类,优先使用物品自身的分类,否则使用默认分类
best_category = next((cat for cat in item_categories if cat in CATEGORIES), category)
download_image(image_url, item, best_category)
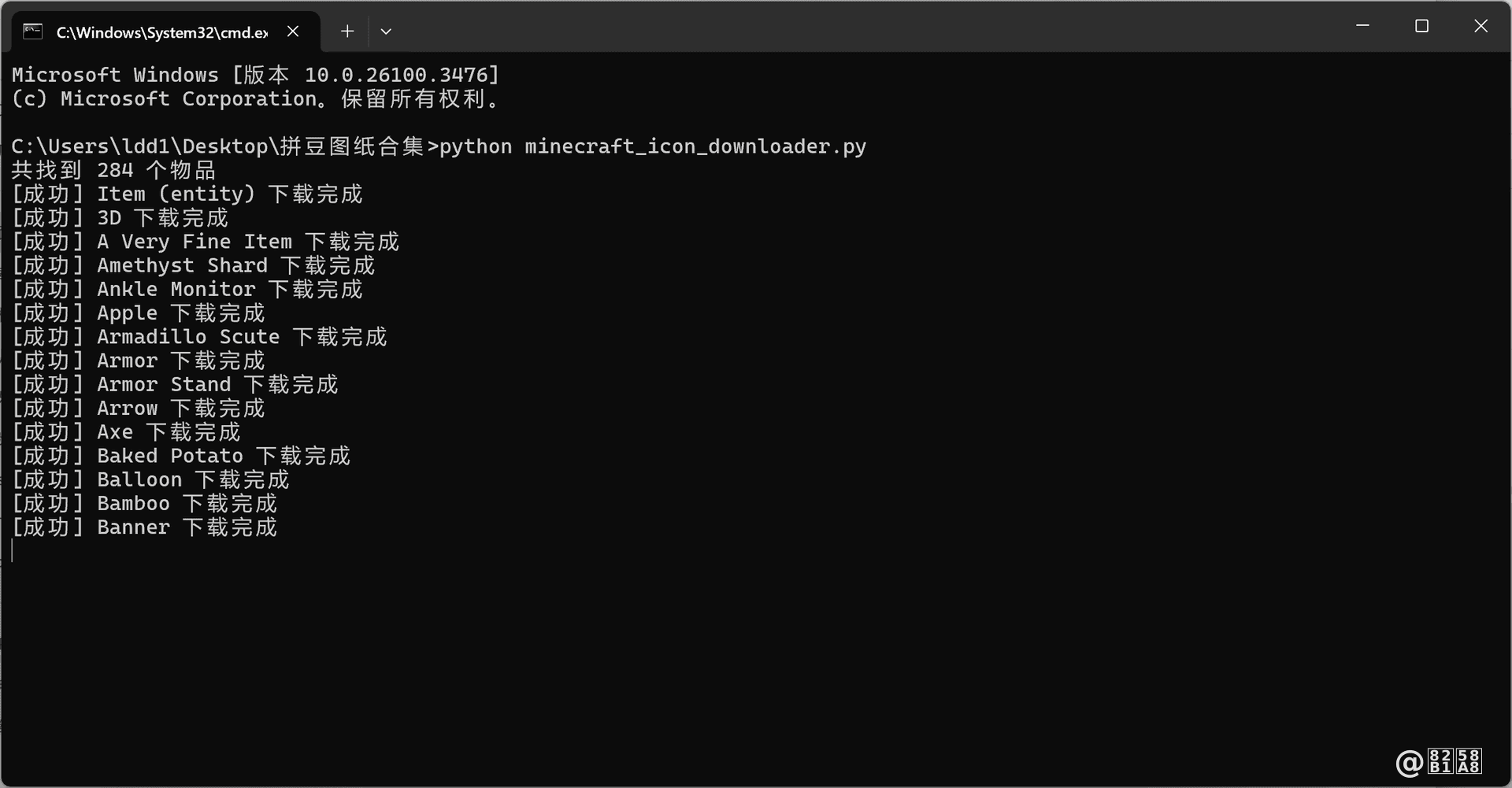
启动py程序,便开始抓取WIKI中的所有图片了
生成图纸
获取所有原画后,下一步就是生成图纸了。
拼豆圈有一个免费开源工具:拼豆辅助工具(如果没有的话我其实还打算开发一个来着……)
我先通过图片尺寸修改工具将所有原图批量修改为16*16尺寸,再手动一张一张通过拼豆辅助工具生成图纸(工具没有批量功能……)
但此时又带来了一个新的问题,图纸没有相应的豆子颜色数量统计。
统计豆子颜色数量
因为拼豆辅助工具在生成图纸后自带颜色统计,通过复制可以得到以下文本:
合计 142
H7 40
B15 23
B8 16
F10 14
F13 8
A10 8
H16 7
F6 7
A7 6
F11 5
A18 2
B23 2
G20 1
F18 1
G5 1
A14 1
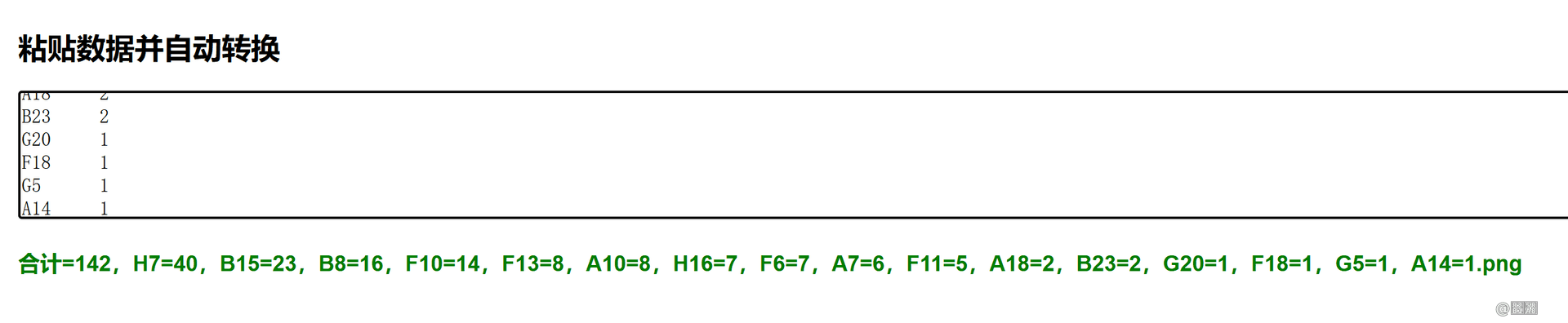
于是我想到了将文件名命名为颜色数量统计的方法,那么就需要编写一个程序,将文本转化为无换行且更易读的字符串。
用html+css+js即可简单实现,当我将文本粘贴到输入框中,会自动生成字符串并写入我的剪切板
这就是完全不想多操作一步的懒再花!
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>数据转换</title>
<style>
body {
font-family: Arial, sans-serif;
padding: 20px;
}
textarea {
width: 100%;
height: 100px;
font-size: 16px;
}
#output {
margin-top: 20px;
font-size: 18px;
color: green;
font-weight: bold;
}
</style>
</head>
<body>
<h2>粘贴数据并自动转换</h2>
<textarea id="inputArea" placeholder="在此粘贴数据..."></textarea>
<div id="output"></div>
<script>
document.getElementById("inputArea").addEventListener("paste", function (event) {
setTimeout(() => {
let inputText = event.target.value;
let lines = inputText.split(/\r?\n/);
let result = [];
lines.forEach(line => {
let parts = line.trim().split(/\s+/);
if (parts.length >= 2) {
let key = parts[0];
let value = parts[1];
result.push(`${key}=${value}`);
}
});
let outputText = result.join(","); // 使用中文逗号
outputText += '.png'
document.getElementById("output").textContent = outputText;
// 复制到剪贴板
navigator.clipboard.writeText(outputText).then(() => {
console.log("已复制到剪贴板:", outputText);
}).catch(err => {
console.error("复制失败:", err);
});
}, 100); // 延迟获取粘贴内容
});
</script>
</body>
</html>
最终效果如图
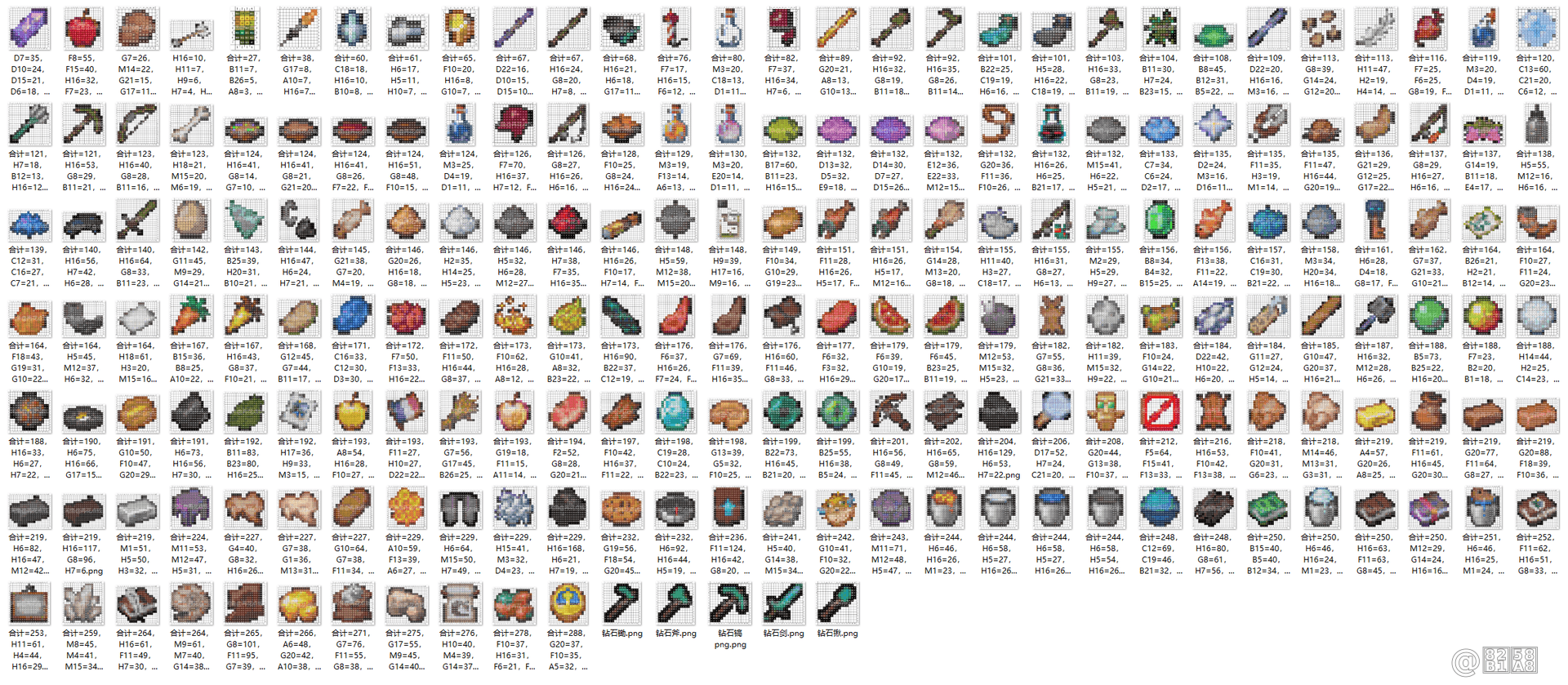
一共100张有效原图,最终进行100次操作生成了这样100张Minecraft图纸
虽然因为像素原画的限制,图纸略微有一些细节上的不足,但终归是达成了自己的需求,总的来说也是一次非常有趣的经历,真是技术改变生活啊!